はてなキーワード: apiとは
既知のCSAMについてはハッシュ化したうえでデータベース化し、疑いのある画像とマッチングするという手法が広くとられています。
perceptual hash‐based detection
LAIONによって確度0.995以上でunsafeと判定されているサンプルを全て抽出し、画像URLをPhotoDNAで検証
マッチしたサンプルをProject Arachnid Shield APIを通してC3P (Canadian Centre for Child Protection)に検証してもらう
CSAM判定されたCLIP特徴を記録
cryptographic hash‐based detection
NCMECの保有するMD5データベースを用いてLAION-5Bに含まれるCSAMを検出
この手法は既にリンク切れになってCSAMか判別できないサンプルに対しても一定の検出を行うことができます。LAIONは各画像のMD5をまとめたものをlaion2B‐multi‐md5, laion2B‐en‐md5, laion1B‐nolang‐md5といった形で公開しており、このMD5をNCMECの保有するデータベースと突き合わせることができます。このcryptographic hash-based手法はrecallが低くなるものの、MD5の一致を見るだけで良いので50億全てのサンプルを走査することができます。
記録したCLIP特徴でk近傍法を行い、データセット全体から類似画像を検索
PhotoDNAで検証
PhotoDNAでは分からなかった画像をダウンロードし、Thornの提供するCSAM分類器で判定
あらたに認定されたCSAM画像のCLIP特徴からk近傍法を行い、上のステップを繰り返す
この類似度検索によってunsafe値に依らない検出を行うことができ、さらにPhotoDNAでマッチしない未知のCSAMも検出することができます。しかしながらC3Pでの検証は人力であり、類似画像をすべて投げるわけにはいきません。そこでThornの分類器によるフィルタリングを挟んでいます。
みつかったCSAMの特徴
あまり詳しい統計は載っていないのですが、Reddit, Twitter, Blogspot, WordPressといったCDNや、XHamster, XVideosといったアダルトサイトのドメインが含まれているようです。またサイトの特徴として"teen models"やヌード、日本の"junior idol"コンテンツが多くヒットしているとしています。
https://qiita.com/__dAi00/items/90521cc333924196a7ba
原文読んでないからそのつもりで
勝者総取りじゃなく、後発でも割と簡単に追いつけるようなものみたいだ。学習データも少なくて済むようになりそうだ。
性能の高さを競うより、今の性能をコンパクトに実現するかを競う段階な感じ。
ChatGPTのAPIの利用料が高すぎて、これを使ってルーチン的なことをする気にはなれない。
Googleに聞いて、情報の真贋がわからない人は、AIに聞いても同じだと思う。結局、3行以上の文章を読めない人向けのサービス。
Keras: The high-level API for TensorFlow
https://www.tensorflow.org/guide/keras
対戦有り難うございました。
いいえ、その説明は正確ではありません。MidjourneyとDALL-Eを単純に比較することは適切ではありません。
1. 価格:
- MidjourneyとDALL-Eは異なる料金体系を持っています。
- MidjourneyにはDiscordベースの無料プランと、商用利用向けの有料プランがあります。
- DALL-Eは、APIを通じて利用が可能で、使用量に基づいた料金体系となっています。
- したがって、「Midjourneyは、DALL-Eの安価なバージョン」という説明は適切ではありません。
2. 技術:
- MidjourneyとDALL-Eは、異なる技術アプローチと実装を採用しています。
- 両者の詳細な技術的特徴は公開されていませんが、アーキテクチャや学習手法に違いがあると考えられます。
- したがって、一方が他方のバージョンであるとは言えません。
- MidjourneyとDALL-Eは、生成する画像の特性や傾向が異なります。
- Midjourneyは、幻想的でアーティスティックなイラストを得意としています。
- DALL-Eは、より幅広いスタイルの画像生成が可能で、写真のようにリアルな画像生成にも強みがあります。
4. 開発主体:
- MidjourneyはMidjourney社によって開発されたのに対し、DALL-EはOpenAI社によって開発されました。
- 両者は独立した企業であり、相互に関連するものではありません。
したがって、「MidjourneyはDALL-Eの安価なバージョン」という説明は、技術的にも概念的にも正確ではありません。両者は独自の特徴を持つ画像生成AIであり、単純に比較することは適切ではないでしょう。
X (twitter) で SITUATIONAL AWARENESS: The Decade Ahead https://situational-awareness.ai/ というのが回ってきて非常に示唆に富むものだったので、DeepL (無料版 API経由) で訳してみた。
この1年で、街の話題は100億ドルのコンピュート・クラスターから1000億ドルのクラスター、そして1兆ドルのクラスターへと移り変わってきた。半年ごとに、役員室の計画にまたゼロが追加される。その裏では、残りの10年間に利用可能なすべての電力契約と、調達可能なすべての電圧変圧器を確保しようとする熾烈な争いが繰り広げられている。アメリカの大企業は、アメリカの産業力を結集させるために、何兆ドルもの資金を注ぎ込む準備を整えている。ペンシルベニア州のシェールフィールドからネバダ州の太陽光発電所まで、何億ものGPUが稼働する。
AGI競争が始まったのだ。私たちは思考し、推論できるマシンを作りつつある。2025年から26年にかけて、これらのマシンは多くの大学卒業生を凌駕するだろう。10年後までには、これらのマシンは私やあなたよりも賢くなり、本当の意味での超知性を手に入れるだろう。その過程で、この半世紀には見られなかったような国家安全保障の力が解き放たれ、やがて「プロジェクト」が始動する。運が良ければ、中国共産党との全面的な競争になり、運が悪ければ全面戦争になる。
今、誰もがAIについて話しているが、何が自分たちを襲おうとしているのか、かすかな光明を感じている人はほとんどいない。Nvidiaのアナリストは、まだ2024年がピークに近いと考えている。主流派の評論家たちは、「次の言葉を予測するだけだ」という故意の盲目に陥っている。彼らが見ているのは誇大広告といつも通りのビジネスだけで、せいぜいインターネット規模の新たな技術革新が起こるのを楽しむ程度なのだ。
やがて世界は目を覚ますだろう。しかし、今現在、状況認識を持っているのはおそらく数百人で、そのほとんどはサンフランシスコとAI研究所にいる。運命の不思議な力によって、私はその中に身を置くことになった。数年前、このような人々はクレイジーだと揶揄されたが、彼らはトレンドラインを信頼し、過去数年間のAIの進歩を正しく予測することができた。この人たちが今後数年についても正しいかどうかはまだわからない。しかし、彼らは非常に賢い人々であり、私がこれまでに会った中で最も賢い人々である。おそらく、彼らは歴史の中で奇妙な脚注となるか、あるいはシラードやオッペンハイマー、テラーのように歴史に名を残すだろう。もし彼らが未来を正しく見ているとしたら、私たちはとんでもないことになる。
各エッセイはそれぞれ独立したものですが、シリーズ全体として読むことを強くお勧めします。全エッセイのPDF版はこちら。
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは~未就学児から~賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生サイズの質的なジャンプが起こると予想される。
AIの進歩は人間レベルでは止まらない。何億ものAGIがAI研究を自動化し、10年に及ぶアルゴリズムの進歩(5以上のOOM)を1年以下に圧縮することができる。私たちは、人間レベルから超人的なAIシステムへと急速に進化することになる。超知能の威力と危険性は劇的なものとなるだろう。
驚異的な技術資本の加速が始まっている。AIの収益が急増するにつれ、10年末までに何兆ドルもの資金がGPU、データセンター、電力の増強に投入されるだろう。米国の電力生産を数十%増加させるなど、産業界の動員は激しくなるだろう。
米国の主要なAI研究所は、セキュリティを後回しに扱っている。現在、彼らは基本的にAGIの重要な機密を銀の皿に載せて中国共産党に渡している。AGIの秘密とウェイトを国家機関の脅威から守るには膨大な努力が必要であり、我々はその軌道に乗っていない。
我々よりもはるかに賢いAIシステムを確実に制御することは、未解決の技術的問題である。解決可能な問題ではあるが、急速な知能の爆発が起きれば、物事は簡単にレールから外れてしまう。これを管理することは非常に緊張を強いられるだろう。
スーパーインテリジェンスは、経済的にも軍事的にも決定的な優位性をもたらすだろう。中国はまだゲームから抜け出してはいない。AGIをめぐる競争では、自由世界の存亡がかかっている。我々は権威主義的な大国に対する優位性を維持できるのか?そして、その過程で自滅を避けることができるのだろうか?
AGIへの競争が激化するにつれ、国家安全保障が関与してくる。アメリカ政府は眠りから覚め、27~28年までに何らかの形で政府によるAGIプロジェクトが立ち上がるだろう。どんな新興企業も超知能を扱うことはできない。SCIFのどこかで、終盤戦が始まるだろう。
もし我々が正しかったら?
――――――――
私はかつてOpenAIで働いていたが、これはすべて一般に公開されている情報、私自身のアイデア、一般的な現場知識、あるいはSFゴシップに基づいている。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel、その他多くの方々の有益な議論に感謝する。初期の草稿にフィードバックをくれた多くの友人に感謝する。グラフィックを手伝ってくれたジョー・ローナン、出版を手伝ってくれたニック・ウィテカーに感謝する。
続き I.GPT-4からAGIへ:OOMを数える(1) https://anond.hatelabo.jp/20240605203849
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
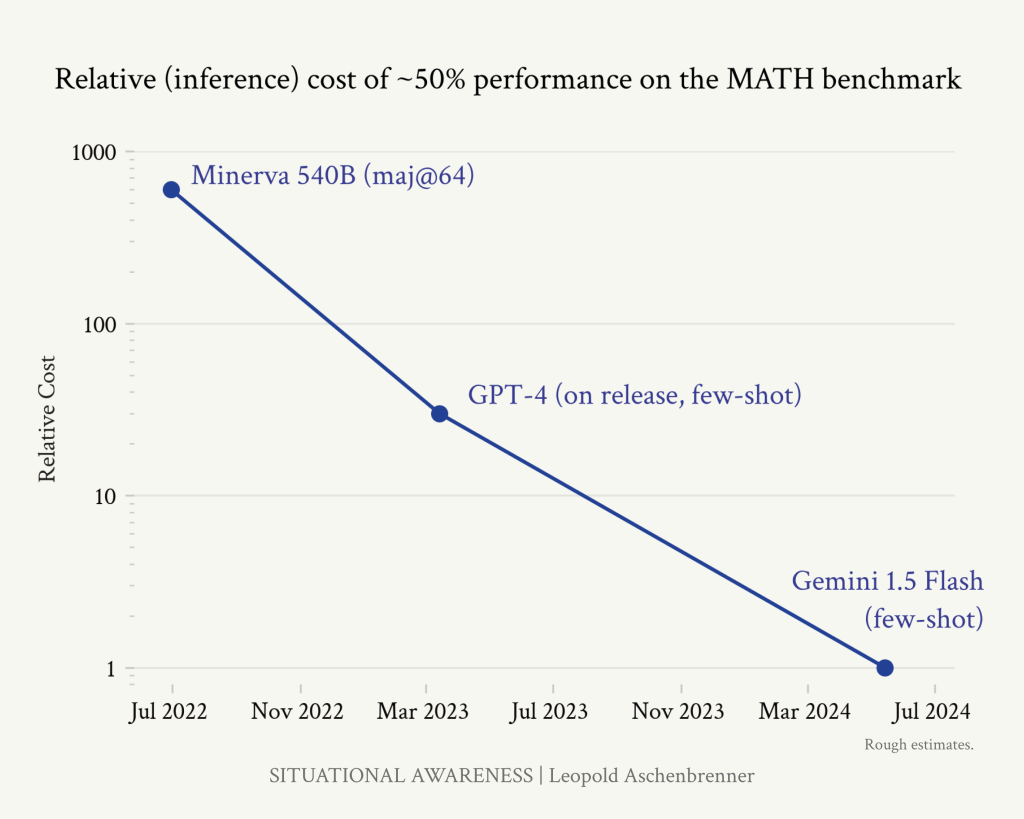
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
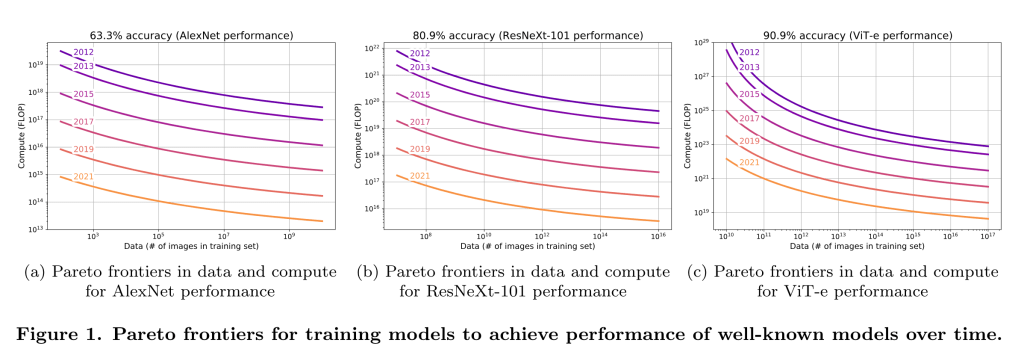
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
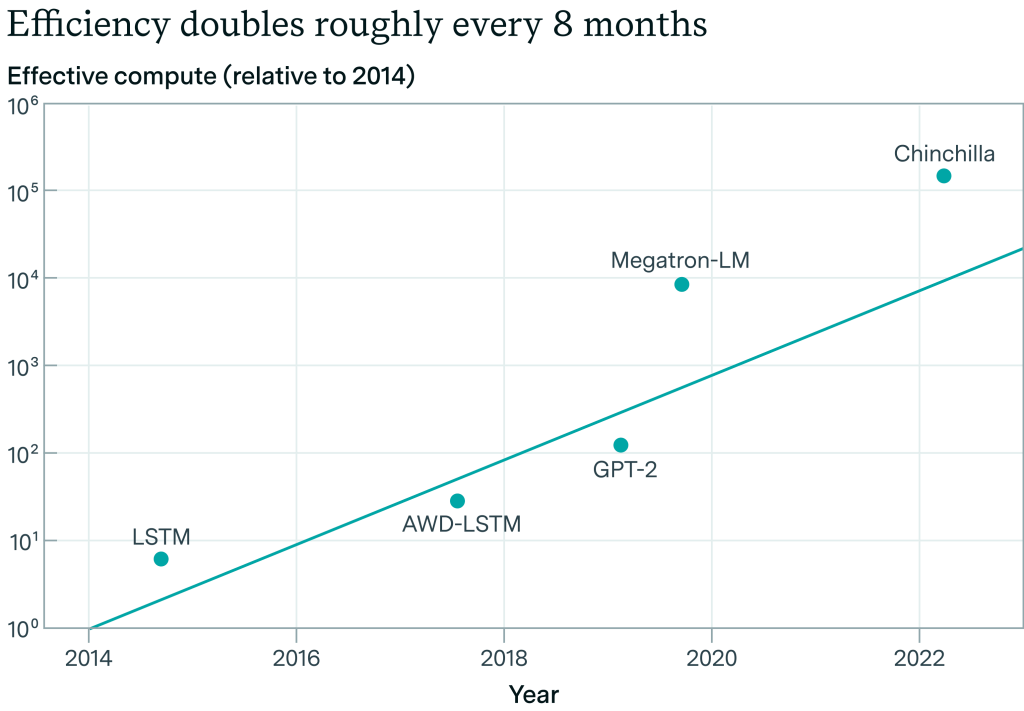
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
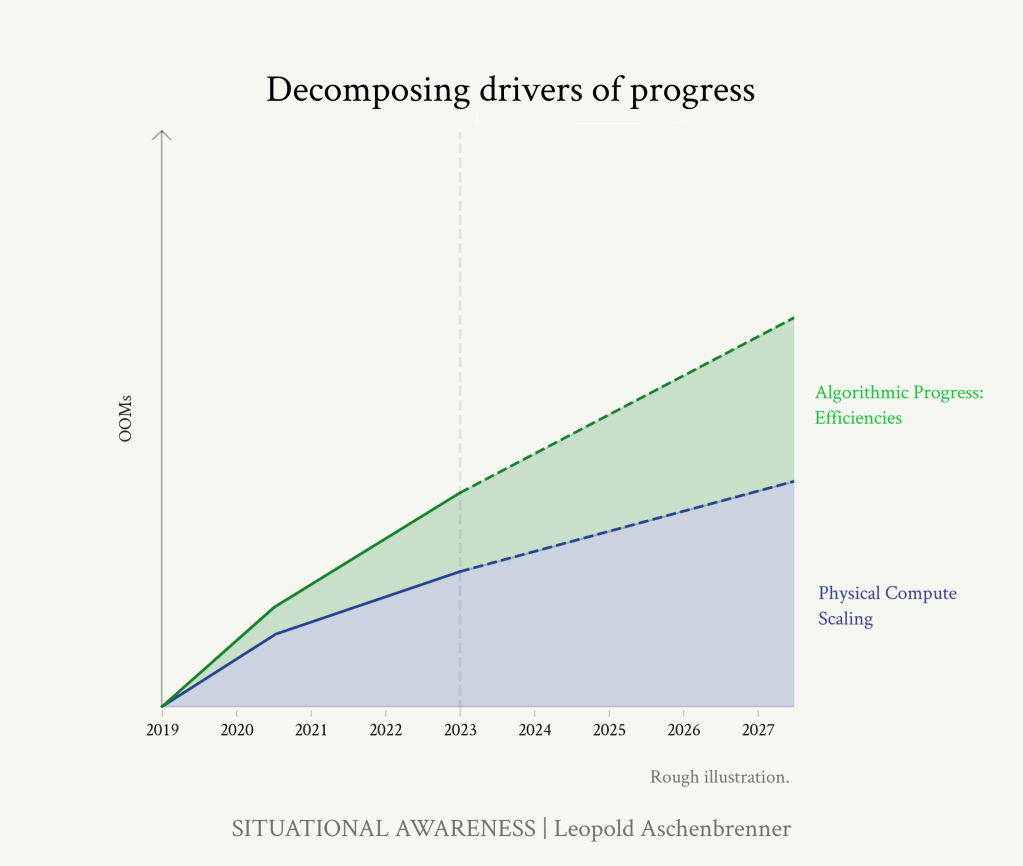
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
別に最初はそれでもいいじゃん。何かの問題や課題を解決するのにChatGPTのAPIだけ使って解決できるならそれでいいし、足りないならその時また調べるでしょ。
学術的な文脈で上記のノリで来られたらオイオイってなるけど、必要性とかの観点で言うならアルゴリズムどうこうは枝葉の話。
だけど老婆心というか古参兵として言いたい事はめっちゃわかるし、今でも情報工学系はやり直したいとは思ってるけど、そのステージではない人に言うのは老害ムーブじゃね?って思ってる。
俺はね、応用力を身につければそれが最短ルートだって言ってんのよ
atcoderをやるのでもいいしオリジナルのWEBサービスを作るのでもいいけど、さすがにchatgptのAPIを使う程度じゃ何も学習してねぇよな
既製APIがないと何もできませんではちょっと複雑な要件に出会ったら何もできなくなるって話ね
例えばさ、ドット積や行列積の演算関数があるとして、それらの関数への入出力の渡し方なんてのは初歩的すぎて話にならないでしょ
バックプロパゲーションをフルスクラッチで効率的に実装するには?みたいな話だとAPIの仕様知識だけじゃ対応できないんだよね
「自分がやりたいことを実現する機能を持った関数や命令、エンドポイントとその入出力を調べ、利用できるようになること」ができないと、
言語組み込みの関数やアセンブリの命令セットを正しく効率的に利用することもできないので、
{kind=link}
{kind=link}
{kind=link}
{kind=link}